DIFFGMM Overview
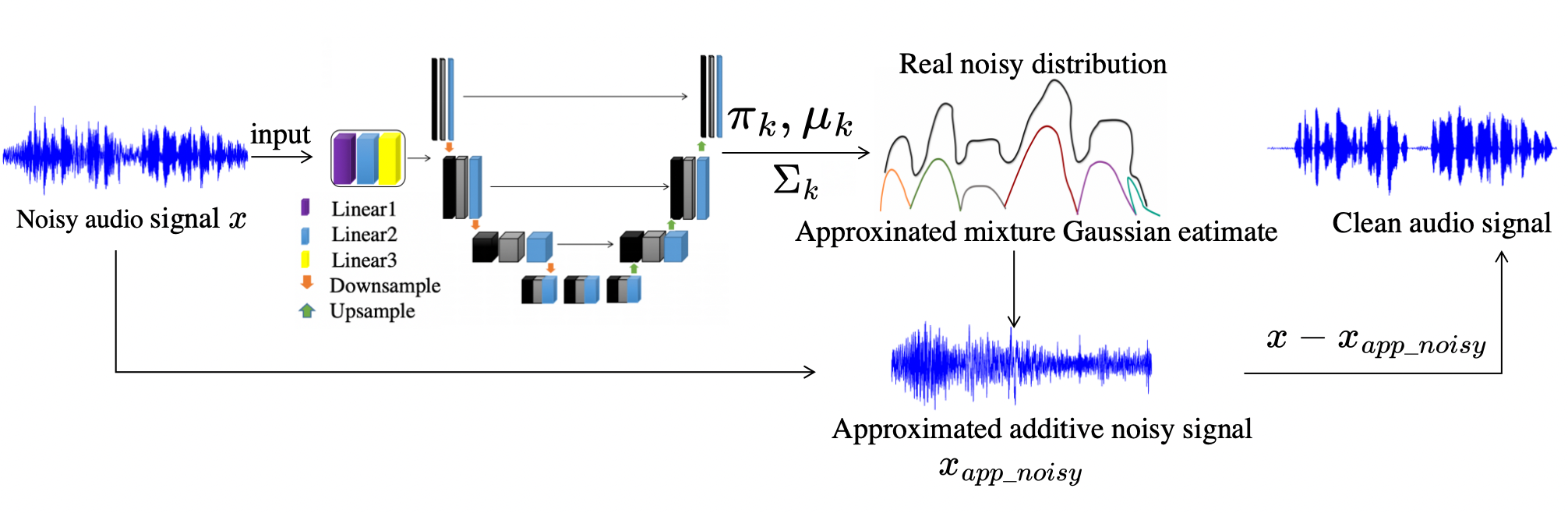
Flowchart of our diffusion Gaussian mixture (DiffGMM) model. Different modules are marked with different color blocks.
Abstract. Recent diffusion models achieved promising performances in audio-denoising tasks. The unique property of the reverse process could recover super clean signals. However, the distribution of real-world noises does not comply with single Gaussian distribution and is even unknown. The sampling of Gaussian noise conditions limits its application scenarios. In other words, one single Gaussian distribution is not enough to represent the original noise distribution. To overcome these challenges, this paper proposes DiffGMM, a denoising model based on the diffusion and Gaussian mixture models. We employ the reverse process to estimate parameters for the Gaussian mixture model. Given a noisy audio signal, we first use a 1D-U-Net to extract features and train linear layers to estimate parameters for the Gaussian mixing model, and we can approximate the real noise distribution. The noisy signal is continuously subtracted from the estimated noise to output clean audio signals. Extensive experimental results demonstrate that the proposed DiffGMM model achieves state-of-the-art performance.
Flowchart of our diffusion Gaussian mixture (DiffGMM) model. Different modules are marked with different color blocks.

sample 1 spectrograms

sample 2 spectrograms

sample 3 spectrograms

sample 4 spectrograms

sample 5 spectrograms